

more on the bangladesh mask study
more on the bangladesh mask study
this is a study in bad study design: a rebuttal of an attempt at rebuttal

goodness, it’s not every day one gets called a liar AND a silly, so (against better judgement) i’m actually going to take the time to rebut lyman here because his claims are badly wrong and serve as a useful foil to further exploration some of the manifold failings of this travesty of a mask study that has received so much fawningly uncritical media attention.
señor stone clearly does not understand this issue or my critique (HERE) as his rebuttal is mostly orthogonal. i suspect this is because he does not understand prospective study design for RCT’s.
he’s also skirting the meat of the study’s many flaws, ignoring the meat of my dissection of them, and trying to draw attention away from how rapidly he’s walking back his claims here. let’s take it from the top:

lyman does not seem to understand the claim i’m making and has wound up misrepresenting it. so let me make it clear:
to make this study work and have a signal of 0.0007 in variance between mask and control arms be valid, you would need to have the two study arms balanced to implausible and likely impossible precision. this did not happen. it could not have happened.
the data to even attempt it (even were it possible) does not exist yet and thus could not have been used to ensure the two study arms were balanced based on the key outcome variable or on prior exposure. it was simply not done.
they used a messy and to my mind useless proxy (past reported cases) without controlling for a key variable in raw case counts: testing level/sample rate.
and even if baseline had been established, using a 5k sample of opt in blood volunteers (random 20% of 25k opt in really) this sort of small sampling by IgG assay could not achieve the level of precision needed due to test error rates alone, much less antibody fade over time or opt in bias.
this is not a strong signal. it’s a VERY weak one, like, need the arecibo radio telescope to hear it weak. a 10% drop does not prove “big.” scale matters. if 10% of people disappeared from the earth, that would be a big signal. if 10% of left-handed redheads who are fans of frank herbert, jane’s addition, play a mean game of badminton, and once jammed with phish disappear from the earth, did anything even happen?
you get the point.
let’s explore this a bit:
taking small, likely non random samples of IgG at time of start does NOT give you a valid prior exposure baseline of sufficient precision to be at all useful in a system like this. IgG rapidly fades, some who got sick and recovered never even generate it, and opt in programs like “come get your blood drawn” are not truly random (because they are opt in) and this introduces big sampling artifacts around choosing to participate that may cluster in unpredictable ways.
if there is variance by geography of prior disease exposure of even, say, 2% (which is very likely) then it completely swamps the 7 in 10,000 signal being identified in masks.
the study’s opt in start date sample of 25k patients (of which they are testing 5k as a baseline) cannot possibly give us this number to sufficient precision. probably, nothing could. and this is the problem.
“we did the best we could, it’s a poor county” does not get you any prizes. it means you never should have done the study because it could never deliver meaningful results outside of error bars.
“they did the best they could with what they had” does not really cut any ice. that’s like me saying “i tried really hard to jump the grand canyon on my skateboard.” i’m not going to succeed.
and i should have known that going in.
and saying “i jumped it +/- 10 miles!” is not terribly useful, is it? because that’s what this sort of cohort imbalance says.
that makes all this following commentary irrelevant.
also note that he’s not arguing that the HAVE a baseline. he’s arguing that they are going to get one.
can’t have a baseline before you finish testing the samples, can you?
one might ask some pointed questions about just who the liar is here and about projecting one’s own failings onto nearby felines…)
this is really simple:
if you cannot measure starting conditions with sufficient precision to be sure your signal is, in fact, a signal and not noise, you have no basis for an experiment.
a simple example: let’s say you have 100 pound sacks of potatoes and you want to test potato depletion that’s likely to be about 50%. for this, you can use a simple scale placed on the sidewalk. an error rate on the initial weigh in of 8 oz or even 1-2 pounds is not going to affect your outcomes much. it’s good enough. if you’re comparing a 100 pound bag to a 100.5 pound bag, you’re still OK in terms of relevant error bars.
but now imagine you are looking to measure a 7 in 10,000 rate of change (as seen in study 0.76% vs 0.69%)
that’s a change of about 1.1 oz per 100 pound bag. do that with a scale precise to 8 oz and you have no signal, it’s all noise. the fact that as a start state, you could not discern a 100 pound bag from a 99.5 pound bag means that any claims about a 1.1 oz change when comparing them is flat out meaningless. it’s noise.
and this is what lyman is missing.
but it gets worse.
there is no “starting seroconversion rate” (and i think he means seroprevalence (called Pprior by the authors) as conversion rate is a process from time a to time b and prevalence is the start point) that can tell you even within an order of magnitude of the purported 0.0007 “signal” what start state prior disease exposure had been.
and we need to know that. pre-existing immunity from prior exposure is critical input variable.
samples were small, not truly random (opt in), and IgG fades. you could easily have 5-10% of bias and variation there and failure to control for testing levels when using reported cases to “balance” the arms could easily be 10X that error.
to ignore that is to ignore noise 100 or 1000X your signal. that is not the path to “valid data claims.”
this alone (p86) could sink you. this randomization and balancing was a mess.

by his own (and the authors’) admission they do not even have these results yet, so how could they, even if it were relevant (which it isn’t) have balanced the study arms for it? they couldn’t.
instead, they randomized cohorts using trailing case data with an incredibly low sample rate (the authors estimate 0.55% for the region) and zero reference to or control for the testing rates and variation thereof that would drive reported cases.

you could be comparing one village with twice the testing and half the disease prevalence of another and think they were the same when you randomized them. this is a serious and irreparable data error. it injects orders of magnitude of possible error.
and clearly, lyman does not understand this or my argument. “raw cases” with a sub 0.55% sample rate, unknown testing heterogeneity, and no control for testing level means you have no real picture of past data. none.
it means this whole study was invalid before it started and frankly, was just never possible at all given the size of signal sought. their picture of start state was nothing like precise enough to make claims about results as small as they portray.
and that’s the clincher
there is no way you can have used data you do not even have yet to randomize and balance the study arms and there was probably no way to do so even if you had had the data.
you could not possibly reach the level of precision required.
this leaves a lot of serious questions about both the authors and about lyman’s takes.
this comment in particular is revelatory:
this is quite the walk back from yesterday when he said:
yesterday, this was the most important research in the whole pandemic. today it’s “give them a break guys, it’s preliminary?”

i would not generally spend so much time dunking on lyman, but calling me a liar while lying gets my fur up.
he’s essentially admitted in his own attempted rebuttal of my criticisms that they cannot possibly have had the data they needed to establish community prior exposure rates at the time they populated the study arms.
this is data yet to come, not data available to establish study arm parity to exacting precision.
you cannot balance for a variable you do not even yet have data for. (and this data would not allow it anyway)
so any “baseline” that may, at some point, exist even if it were valid (and it’s not) could not possibly have been used to balance the study. surely even lyman adheres to a unidirectional model of experienced time… (hard to run a study of a time interval if you don’t)
this makes the whole study into (at best) a retrospective, not a prospective, and in reality, renders it near certain gibberish awash in statistical noise, data farming, and error bars towering over tiny signal range.
and it just keeps getting funnier as he gets more and more wound up.
i suppose many things look like gibberish when you cannot read the words on the page properly. “reading, it’s fundamental”
lyman acts as if the complex social outcomes from pro-masking interventions are 1-2 variable issues and ignores that we have NO IDEA what else may have changed. not knowing about a confound/correlate does not remove it. this is why a good experiment seeks to isolate all but one variable and systems where this is not possible are not susceptible to analysis at this level of precision.
“main effect is significant, many subgroups aren't" is nonsense when you have no idea what was affected. you can always stack all “outcome” into a dependent variable by ignoring other variables.
the effect was 0.0007 in a system that likely had 1-10% intrinsic error at start that was not accounted for.
you can read his whole “rebuttal” here presuming he does not take it down and i recommend doing so because perhaps the most interesting issue in it is what it does not say: anything relevant about any of the other issues raised. (he’s still feverishly adding to it, so it may also have grown post this publication)
there are many glaring problems with this study any one of which would completely invalidate it.
the biggest problem is what i laid out around the “open label” nature of the study combined with moral suasion used to drive behavioral changes.
either this one veers into bad faith or lyman is really not seeing the picture.
he would have us believe that control and mask faced the same pressures when one had community leaders pushing masks, signage, nudging, videos, and even police and contingent cash payments to make people mask and raise awareness and change behavior.
surely, something caused the big divergence in mask adoption.
it was not “observers.”
the whole point of the study was the effect of interventions on behavior.

and lyman is hand waving it away.
that which can cause a 29% point change in masking could surely drive a 1% change in non-propensity to report symptoms of illness if subjects (who knew they were in the active arm) sought to please researchers (or keep access to monetary rewards, avoid shame, or simply ignore a cough because they felt safer). we’re looking at exactly those whose behavior was already changed. but they just changed one attitude in perfect univariate fashion to 0.0007 precision? seems implausible.
these are all well established issues in studies. it’s why they use placebo controls.
there is a reason the vaccine studies injected saline so you did not know if you were vaxxed. proposing not to do so would get you laughed out of the FDA. yet that is exactly what was done here. there is no placebo mask and there is no valid group truth standard because all reporting was self reporting and because, laying out strong messaging on “mask up for safety” it’s 100% clear the subjects knew what outcome the researchers favored.
that’s unfixable sample pollution.
you’d need to test EVERYONE in order to overcome this issue and clearly that was never possible.
folks as steeped in behavioral modification as these authors are would clearly have known that. (and if they did not, it’s hard to take their competence seriously as this is trial design 101)
to ague this does not inject greater than 1% bias is literally impossible, and 1% bias would be 14X the signal purported to be measured.
and that is why i raised this issue:
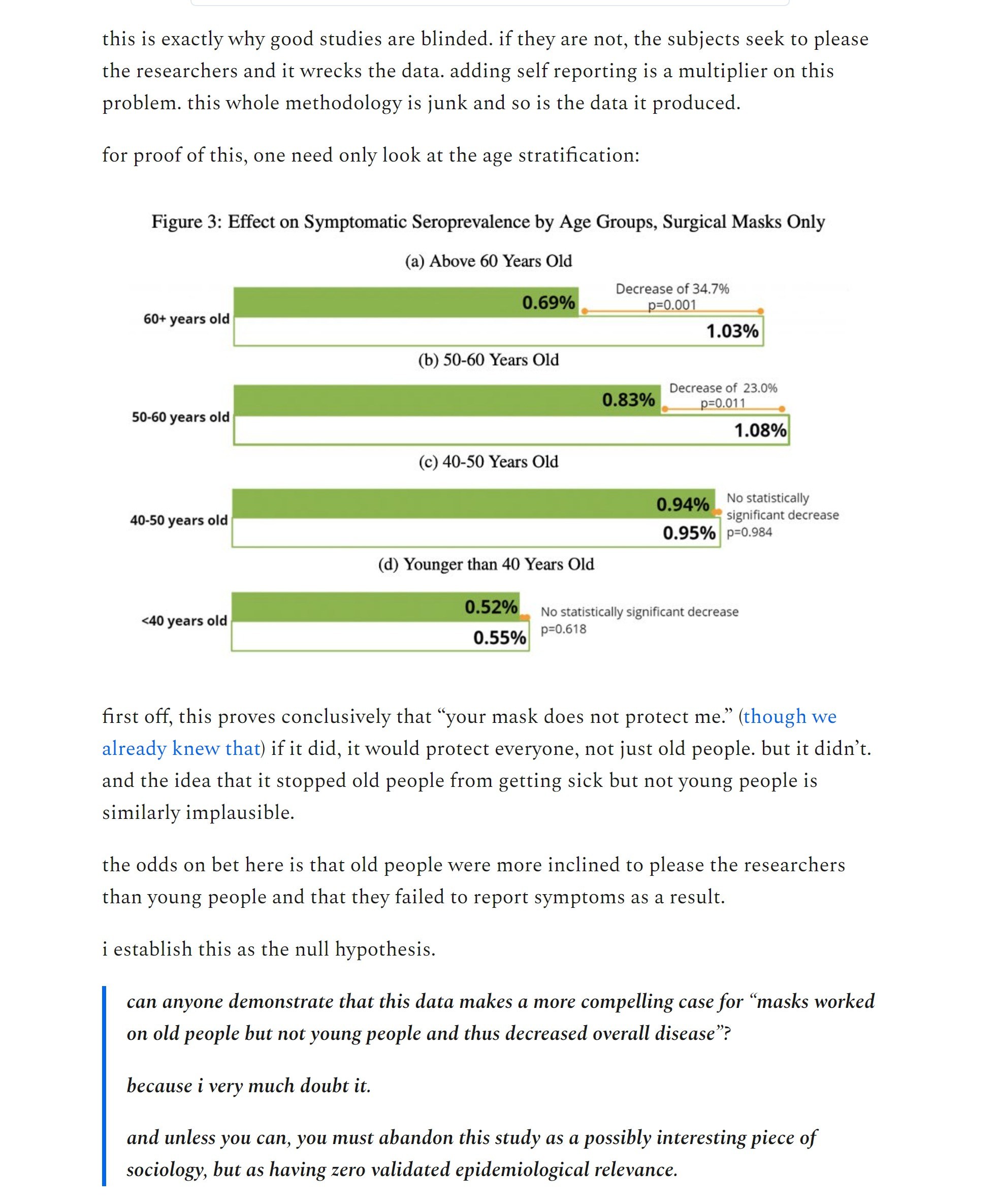
the idea that the cajoling used to affect mask wear would also affect other attitudes seems obvious. i see zero way to rule it out.
the very people who were convinced to wear masks need to be shown to not have changed their attitudes even the teensiest little bit about reporting symptoms.
i’d love to see lyman (or the study authors) address this null hypothesis and prove “identical attitudes to reporting symptoms to 4 decimal places among those convinced to adopt masks” is the more likely state of the world.
(keep in mind this burden of proof is on them, not us if they wish to show a valid study)
i’ll bet they cannot and that means this “study” is meaningless except possibly as a sociology footnote about how older bangladeshis are more likely to seek to please researchers/susceptible to peer and social suasion than young ones when faced with widespread pressure in their communities.
he makes this claim:
“The thing to understand is this study has been enormously publicized for *months* now, the method is widely understood and conventional, and all the critics had all the time in the world to go ahead and say what they thought of the design.”
but it is is simply wrong.
everything about this study design was irretrievably bad and anyone familiar with medical study design will see the flaws pop like taking a blacklight to a hotel bedspread. “well you did not complain before so you cannot complain now” is not much of an augment, is it? it’s just more hand waving.
this methodology looks like a poorly designed sociology or anthropology study. it’s not within a country mile of being a valid medical study.

I hope I never get dunked on by Bad Cat. It's like watching a video where someone gets nailed in the nuts by a dodgeball. You can't help but wince when reading.
Well written. You actually made me nostalgic for statistical analysis class.
...and aside from me and a vanishing number of gatofans, no one will ever see it. Hundreds of thousands, though, will see Lyman's apparently unopposed "yas slay kween" rebuttal and hear that.
"Hands up, don't shoot" is the part everyone remembers.